What's the difference between Observability & Monitoring?
Observability is core to SRE activities and success

Hi Im Andy 👋
I'm a Site Reliability Engineering Architect who's been in the industry over 20 years covering Observability, Capacity, Automation, Site Reliability and Chaos Engineering. I live in North Manchester in the UK, where I enjoy following Manchester United (season ticker holder), running, golf, gigs and sometimes a bit of cooking and of course technology 🚀
I often get asked what is the difference between observability and monitoring and should observability replace monitoring? Lets take it back to the premise of what traditional monitoring is. This is my first article in my Site Reliability Engineering series.
I have been involved in monitoring over 20 years and the design, architecture and implementation of a whole range of monitoring tools across both open source and enterprise.
Monitoring is about the known knowns and traditionally this would involve the templating up of these scenarios and coding them into the monitoring stack for infrastructure and application issues. This involves working with SMEs around the end to end service and what could go wrong factoring in service degradation, risk (via reduced resilience) and status via thresholding and baseline of the application or service. This is both time consuming and an acceptance that if a scenario hasn't been templated then this would drive continuous improvement via RCA.
I think a good example is that traditionally we would light up dashboards like a Christmas tree 🎄 if something went wrong or a node disappeared. However, this is perfectly normal in a containerised environment due to their ephemeral nature. It’s all about how the service is impacted. The days of a traditional event console are also numbered.
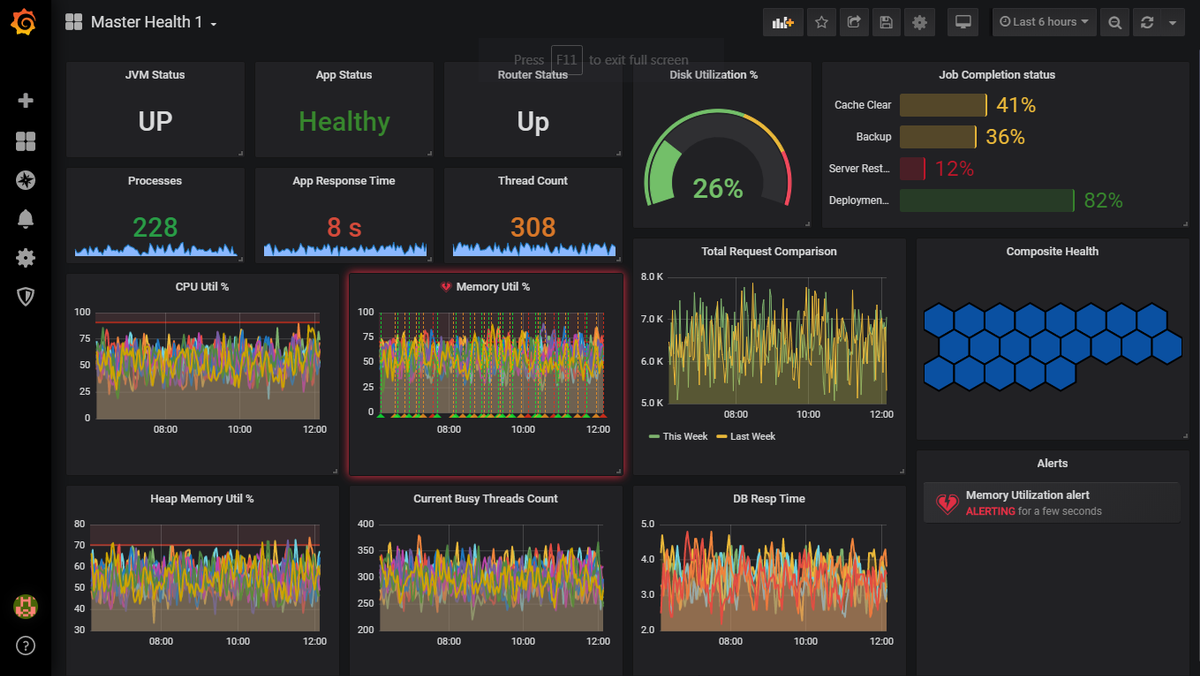
One of the most common challenges with monitoring is the amount of noise that it creates which makes it difficult to understand the real issues from the false alarms. Even with count and time based correlation capabilities. The primary reason for this stems from the fact that monitoring is typically applied as an isolated, disconnected system which monitors a component of a service as an individual entity, and not as a piece of a larger ecosystem with dependencies and integrations affecting one another. This ends up being a system which at the most is best at stating what is broken in a service at a symptomatic level, without really stating what might have caused it or led to that situation.
Observability (or O11y👀 don't shoot the messenger) is a term borrowed from the world of control theory which is defined as the ability of a system to provide insights of its internal state based on how its exterior is behaving. When applying this to our paradigm, it means that observability is a property associated with an application, rather than an implementation on the application and its associated components.
By moving to modern technologies and cloud we create a proliferation of object, services and metrics, a metric explosion if you like. Traditional approaches to monitoring will not work. You can’t have a static threshold or policy defined for every scenario, managed by humans, it’s impossible. As humans, we are all subject to cognitive limitation, algorithms on the other hand are capable of processing millions of events and deriving meaning from large datasets. Services are the new focal point, it’s a different paradigm (customer impact, service performance/availability and risk).
The Three pillars of Observability
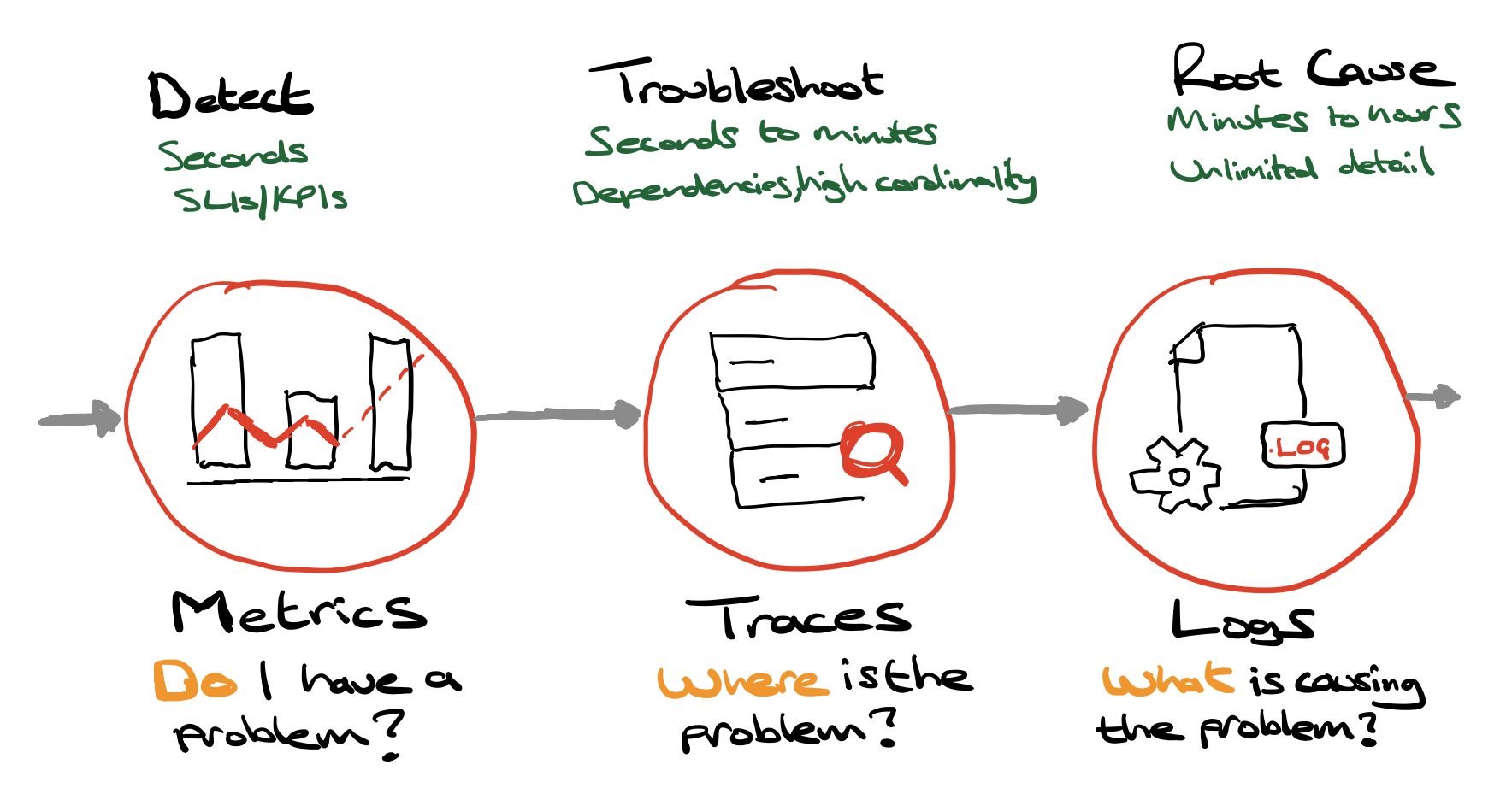 I would argue metrics, traces and logs are merely the 3 pillars of telemetry needed.
I would argue metrics, traces and logs are merely the 3 pillars of telemetry needed.
They all overlap
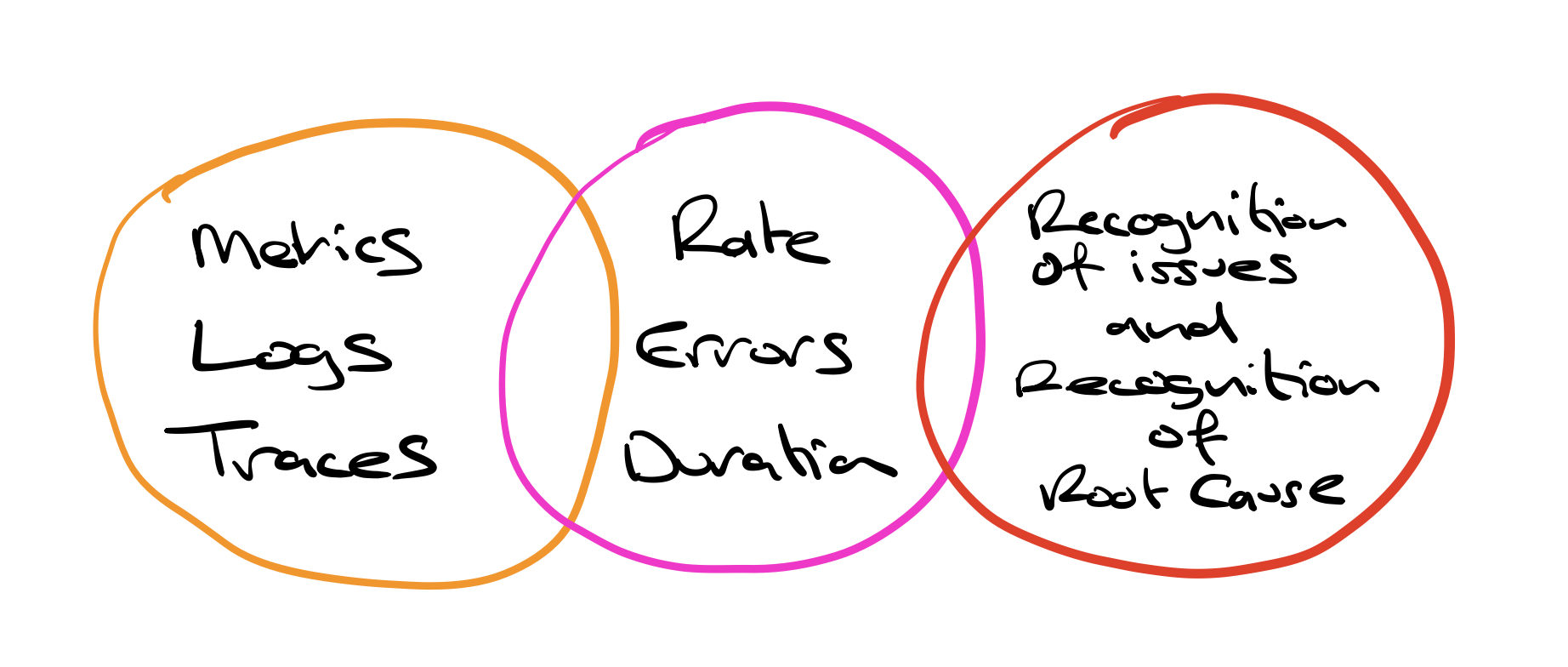
Logs can yield metrics Traces can yield metrics But you need all three
While all three data types are treated separately, they actually all overlap. Logs can yield metrics. Traces can yield metrics. Metrics can point you to the right trace or the right log. With metrics, traces and logs, you can recognise issues faster to find the underlying root cause
Observability is about finding out why and whats changed. Monolithic applications often fail in predictable ways. Modern applications are too complicated to know all of the ways your application can fail. Observability allows you to ask the right questions.
So, Monitoring is a subset of Observability
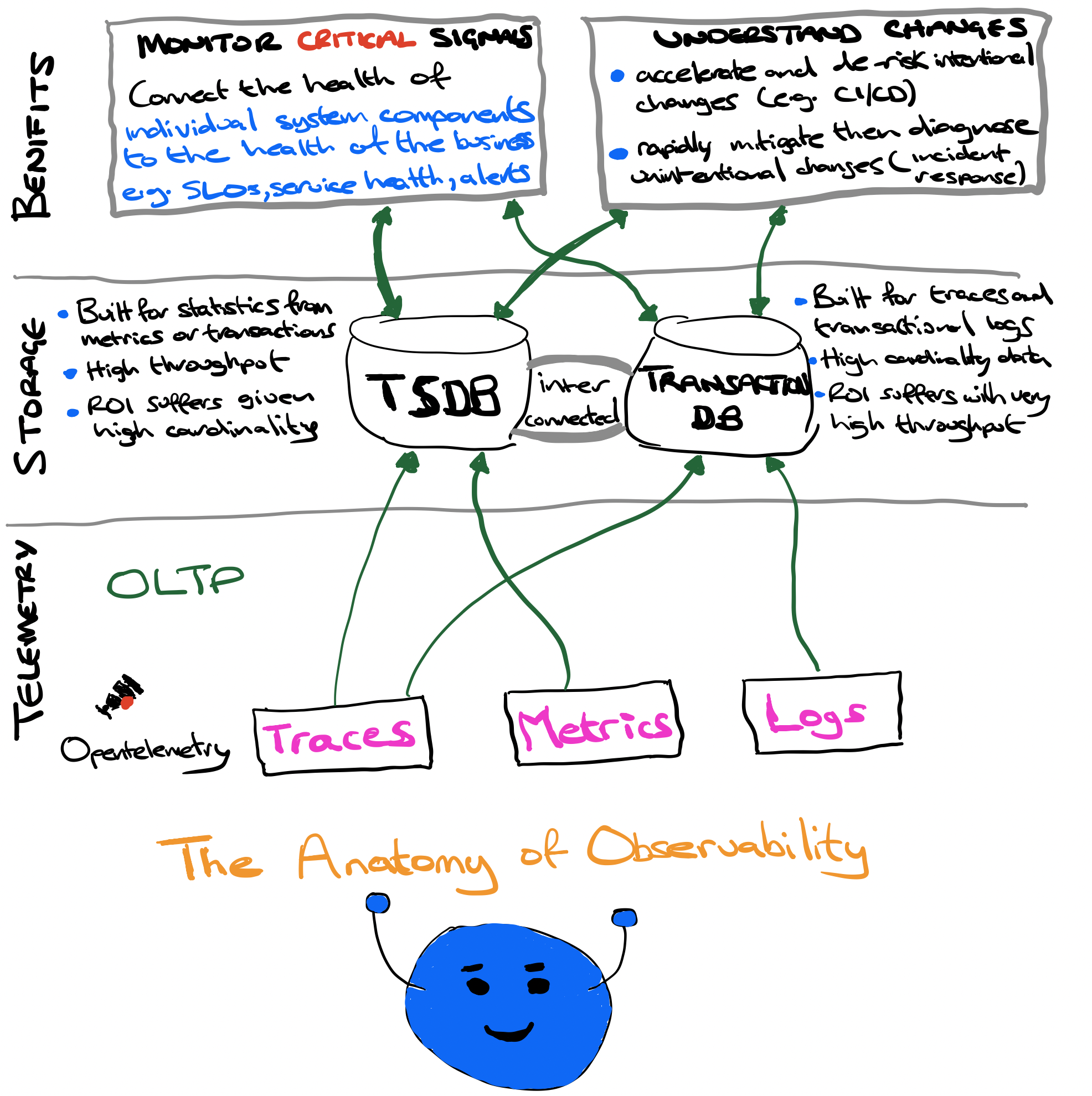
Observability benefits divide neatly into two categories:
- understanding health (i.e. monitoring)
- understanding change (i.e. finding insights and signals in the firehose of telemetry).
Somewhere along the way
monitoringwas thrown under a bus, which is unfortunate. If we define monitoring as an effort to connect the health of a system component to the health of the business then it’s actually critical and ripe for innovation such as SLOs (more on this in a later blog)
Monitoring got a bad name because operators were trying to monitor every possible failure mode of a distributed system. That doesn’t work because there are too many of them as outlined right at the start of this article. Also that’s why there are always far too many dashboards in a company trying to show status for every single scenario.
Monitoring really doesn’t have to be that way. It can actually be very clarifying and there’s plenty of room for innovation. I’d argue that SLOs, done properly, are what monitoring can and should be (or become).
So what if we do things differently? What if we do things right? We treat Monitoring as a first-class citizen, albeit only a part (a subset remember) of observability. Now we create monitoring for the signals that best express and predict the health of each component in our systems.
What are the goals of Observability
Building observability for a system should never be treated as a goal in itself. There needs to be clarity on the areas of improvement that observability is targeting. This helps in ensuring that observability is aligned with the expectations of the stakeholders and is also customised to the organisation’s specific needs.
Service Reliability
Observability provides insights into a service like the performance of the service relative to the pre-defined baseline. The metrics could be providing details on the key areas of availability and latency of the service. Observable services are able to provide proactive alerts when a system is either deviating or is about to deviate from the expected path on these two key areas. Getting notified on this deviation at the earliest enables the application support teams to take corrective actions to either completely eliminate or reduce the impact to the service.
Operational Efficiency
This is one that is often totally ignored or given less focus by many SRE teams.
Along with improvements in the areas of mean time to recover (MTTR) and mean time to detect (MTTD), observability also directly impacts another important area which is now being termed as the MTTI or mean time to investigate. MTTI is defined as the time taken by an organization to start investigating the cause and the path for solving the issue since the issue was detected. The insights enabled by observability can shorten this period by pinpointing the cause upfront and helping the team get on with resolving the issue at the earliest. As the observable system emits the right signals at the right time and has the warning signals built in, they enable the operations teams to efficiently spend their time and avoid focusing on irrelevant areas. This helps improve the operational efficiency of the organisation.
There are also other important indicators that can be used here but the take away point is to measure and track everything.
Security and Compliance
By providing a 360-degree view of a service’s state which is achieved by correlating logs from multiple systems like applications, integration points, network and hosting infrastructure; an observable system is able to provide critical insights into the security and compliance requirements requirements of a system. With correlation between network patterns, data usage, and access logs, certain security behavior of the system can be analyzed and alarms can be triggered for any anomalies. Any organization that wants to achieve high standards of security should start thinking about observability with focus on security. Having a SIEM (security information and event management) which is able to aggregate, correlate, and notify on security anomalies helps organisations monitor user and system behaviours related to security. Having an integrated SIEM and Observability platform also adds greater value.
So in Summary
Monitoring will never be superseded by Observability as they are complimentary approaches. They both need each other.
It’s not just part of Observability’s DNA, it’s a vital chromosome ! The challenge is to evolve Monitoring, and to use it as platform and bridge for the patterns and insights in our telemetry that can explain change.
Remember the single most important question in Observability is
what caused that change
